

Data Mining là một trong những lĩnh vực quan trọng nhất thuộc công nghệ cùng với Data Science. Tuy nhiên Data Mining phụ trách việc phân tích và quản lý dữ liệu để từ đó dự đoán cho kế hoạch tương lai. Vậy Data Mining là gì? Cách thức hoạt động và những điều bạn cần biết trong công cụ khai phá dữ liệu hàng đầu này! Bạn có thể tham gia khóa học Data Mining hoặc theo dõi những thông tin hữu ích Wiki Lanit đã tổng hợp cho bạn dưới đây.
Data Mining là gì?
Data mining (khai phá dữ liệu) là một quá trình phân loại và sắp xếp các tập hợp dữ liệu lớn nhằm xác định các mẫu số. Từ các mẫu số đó sẽ thiết lập nhiều mối liên hệ có liên quan và giải quyết các vấn đề. Các doanh nghiệp có thể dự đoán xu hướng tương lai nhờ vào MCU khai phá dữ liệu.
Data Mining là một quy trình phức tạp, kết hợp việc sử dụng kho dữ liệu chuyên sâu và các công nghệ tính toán. Hơn thế, Data Mining không chỉ dừng lại ở việc trích xuất dữ liệu, mà còn bao gồm các khía cạnh như làm sạch, biến đổi, tích hợp dữ liệu và cả phân tích mẫu. Để học và hiểu rõ về lĩnh vực này, hầu hết mọi người cần tham gia các khóa học Data Mining.
Có nhiều tham số quan trọng trong Data Mining có thể kể đến như quy tắc kết hợp, phân cụm, phân loại và dự báo. Dưới đây là một số tính năng chính thuộc Data Mining:
- Dựa trên xu hướng trong dữ liệu để dự đoán các mẫu số.
- Dự đoán kết quả bằng tính toán
- Phân tích từ thông tin phản hồi.
- Hướng tới các cơ sở dữ liệu có quy mô lớn
- Hiển thị dữ liệu phân cụm một cách trực quan
Những ưu và nhược điểm của Data Mining là gì?
Về ưu điểm:
- Data Mining giúp tổ chức thu thập dữ liệu dựa trên kiến thức, tạo nền tảng cho quá trình ra quyết định.
- Nó hỗ trợ tổ chức trong việc thực hiện các sửa đổi phức tạp để tạo ra lợi ích trong hoạt động và sản xuất.
- So với các ứng dụng dữ liệu thống kê khác, việc thực hiện Data Mining có thể tiết kiệm chi phí.
- Data Mining tạo điều kiện thuận lợi để tự động khám phá các mẫu ẩn, dự đoán xu hướng và hành vi.
- Nó hỗ trợ việc xây dựng những hệ thống mới và cải thiện các nền tảng hiện có.
- Quy trình Data Mining phù hợp giúp người dùng tiếp cận và phân tích lượng dữ liệu lớn trong thời gian ngắn.
Về nhược điểm:
- Các công cụ Data Mining thường đa dạng và phức tạp, yêu cầu người sử dụng phải được đào tạo để sử dụng và khai thác chúng.
- Nếu các kỹ thuật Data Mining không chính xác hoặc bị sai sót, có thể dẫn đến kết quả đầu ra không chính xác hoặc nghiêm trọng trong một số trường hợp.
- Mỗi công cụ Data Mining sử dụng các thuật toán và phương pháp khác nhau, khiến việc lựa chọn công cụ phù hợp với tổ chức trở nên khó khăn.
- Một số tổ chức có thể bán dữ liệu của họ cho bên thứ ba để kiếm tiền, điều này có thể dẫn đến vấn đề về quyền riêng tư và bảo mật dữ liệu.
Ứng dụng của Data Mining là gì?
Data Mining có thể ứng dụng trong nhiều trường hợp như:
- Kiểm soát gian lận
- Nghiên cứu thêm ứng dụng khai phá dữ liêu khác
- Phân tích thị trường chung và thị trường chứng khoán nói riêng
- Quản lý và hạn chế các rủi ro
- Phân tích giá trị khách hàng

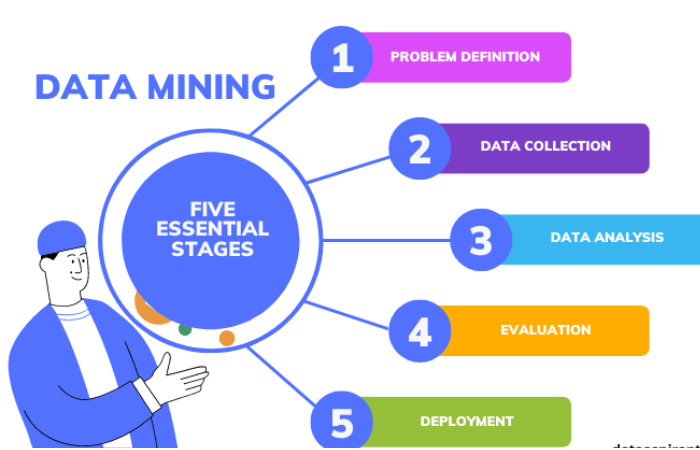
7 giai đoạn trong Data Mining là gì
Tổng kết từ các tài liệu và các khóa học Data Mining uy tín, có thể đưa ra quá trình khai phá dữ liệu phức tạp gồm 7 giai đoạn như sau:
Giai đoạn 1: Xây dựng mục tiêu
Data Mining bắt đầu với việc thiết lập mục tiêu cụ thể. Trong Data Mining, bước đầu tiên chính là xác định được mục tiêu cụ thể. Điều này bao gồm việc xác định những câu hỏi quan trọng cần được trả lời. Tuy nhiên, ngoài việc xác định mục tiêu, chúng ta cũng cần xem xét, cân nhắc giữa chi phí và lợi ích.

Nếu bạn hoặc công ty bạn có nguồn tài chính dồi dào, thì chi phí có thể không phải là vấn đề quan trọng và bạn có thể sẵn sàng đầu tư lớn để đạt được kết quả mong muốn từ Data Mining. Tuy nhiên, sự đánh đổi giữa chi phí và lợi ích luôn phải được xem xét khi xác định mục tiêu và phạm vi dự án Data Mining là gì. Việc đạt được mức độ chính xác cao trong Data Mining thường đòi hỏi đầu tư lớn về tài nguyên và cả thời gian. Do đó, việc cân nhắc giữa chi phí và lợi ích để đạt được mức độ chính xác mong muốn là một phần quan trọng trong việc đặt mục tiêu cho dự án Data Mining.
Giai đoạn 2: Lựa chọn dữ liệu
Kết quả của một dự án Data Mining lớn mạnh phụ thuộc chủ yếu vào chất lượng của dữ liệu sử dụng. Có những lúc chúng ta có dữ liệu sẵn sàng để xử lý, chẳng hạn như trong trường hợp của các nhà bán lẻ với cơ sở dữ liệu lớn về giao dịch và thông tin khách hàng. Tuy nhiên, đôi khi, dữ liệu có thể không sẵn sàng để sử dụng. Trong những trường hợp như vậy, bạn cần xác định các nguồn dữ liệu thay thế hoặc thậm chí phải lên kế hoạch thu thập dữ liệu mới.

Loại dữ liệu, khối lượng, và tần suất thu thập dữ liệu này đều có tác động trực tiếp đến chi phí thực hiện khai thác dữ liệu. Vì vậy, việc xác định đúng loại dữ liệu cần thiết cho Data Mining là gì chính là yếu tố quan trọng để đảm bảo sự đáng đầu tư và hiệu quả trong quá trình tiến hành dự án này.
Giai đoạn 3: Trước khi xử lý dữ liệu
Tiền xử lý dữ liệu đóng vai trò quan trọng trong Data Mining. Ban đầu, dữ liệu thường tồn tại ở dạng thô, không theo quy tắc, chứa thông tin sai lệch hoặc không liên quan. Thậm chí, dữ liệu có thể bị thiếu thông tin. Trong giai đoạn trước khi xử lý, chúng ta cần xác định và loại bỏ các thuộc tính không có ý nghĩa trong dữ liệu. Bên cạnh đó kịp thời phát hiện và xử lý các điểm dữ liệu bất thường. Ví dụ, lỗi nhập liệu có thể gây ra sự sai lệch hoặc phân tích thiếu chính xác giữa các cột dữ liệu. Yêu cầu đặt ra là cần kiểm tra tính toàn vẹn của dữ liệu.

Cuối cùng, chúng ta cần phát triển phương pháp để xử lý dữ liệu bị thiếu và xác định xem dữ liệu bị thiếu có tính ngẫu nhiên hay có sự hệ thống. Nếu dữ liệu bị thiếu ngẫu nhiên, chúng ta có thể sử dụng các giải pháp đơn giản để xử lý chúng. Tuy nhiên, khi dữ liệu bị thiếu có sự hệ thống, chúng ta cần xác định nguyên nhân gây ra sự thiếu sót trước khi đưa ra giải pháp.
Giai đoạn 4: Transform (biến đổi dữ liệu)
Sau khi đã hoàn tất tiền xử lý dữ liệu, bước tiếp theo là phải xác định định dạng lưu trữ dữ liệu phù hợp. Trong Data Mining, chúng ta thường cố gắng giảm số lượng thuộc tính xuống mức tối thiểu mà vẫn giữ lại các thông tin quan trọng để giải thích một số trường hợp. Điều này đôi khi đòi hỏi chúng ta phải áp dụng các thuật toán giảm dữ liệu như Principal Component Analysis (PCA) để thực hiện việc này. Ngoài ra, các biến có thể cần phải được chuyển đổi để giúp chúng ta hiểu rõ hơn về các hiện tượng mà chúng ta đang nghiên cứu.

Trong quá trình này thông thường chúng ta cần chuyển đổi các biến từ dạng này sang dạng khác để phù hợp với mục tiêu nghiên cứu. Việc này giúp chúng ta thu thập thông tin về các tương tác phi tuyến tính trong các biểu đồ và mô hình dữ liệu.
Giai đoạn 5: Lưu trữ dữ liệu
Dữ liệu sau khi đã được chuyển đổi cần được lưu trữ trong định dạng thuận tiện cho quá trình Data Mining. Điều quan trọng là dữ liệu phải được lưu trữ trong định dạng cho phép các Data Scientist đọc, ghi một cách nhanh chóng và không bị hạn chế. Trong quá trình, khi các biến mới được tạo ra, chúng sẽ được ghi lại vào cơ sở dữ liệu gốc. Điều này làm cho việc sơ đồ lưu trữ dữ liệu trở nên quan trọng, đảm bảo tính hiệu quả của việc đọc và ghi dữ liệu vào cơ sở dữ liệu.

Ngoài ra, việc lưu trữ dữ liệu trên các máy chủ hoặc phương tiện lưu trữ đồng nhất giúp bảo vệ dữ liệu và ngăn chặn thuật toán Data Mining phải tìm kiếm dữ liệu rải rác trên nhiều nơi khác nhau. Bảo mật và quyền riêng tư của dữ liệu cũng cần được đặt lên hàng đầu, đảm bảo an toàn cho dữ liệu lưu trữ.
Giai đoạn 6: Data Mining
Sau khi dữ liệu đã được xử lý, chuyển đổi và lưu trữ một cách cẩn thận, giai đoạn tiếp theo là quá trình khai thác dữ liệu. Quá trình này bao gồm việc sử dụng các phương pháp phân tích dữ liệu, các phương pháp tham số và không tham số, cùng với việc áp dụng các thuật toán Machine Learning.

Để bắt đầu, việc trực quan hóa dữ liệu thường rất quan trọng. Nó giúp chúng ta thấy dữ liệu từ nhiều góc độ, phát hiện các xu hướng và mô hình ẩn bên trong dữ liệu thông qua việc sử dụng các công cụ vẽ đồ thị hiện đại trong các phần mềm Data Mining.
Giai đoạn 7: Đánh giá kết quả
Sau khi biết được kết quả trích xuất từ quá trình Data Mining là gì, bước tiếp theo là đánh giá chất lượng của các kết quả này. Quá trình đánh giá có thể bao gồm kiểm tra khả năng dự đoán của các mô hình nhằm xem xét hiệu suất của các thuật toán và đánh giá mức độ hiệu quả của chúng trong việc tái tạo dữ liệu. Hoạt động này được gọi là “dự báo trong mẫu”. Ngoài ra, kết quả cũng cần được chia sẻ và trình bày trước các bên liên quan (stakeholders) để thu thập phản hồi. Sau đó, phản hồi này sẽ được tích hợp và áp dụng trong các vòng lặp tiếp theo của quá trình Data Mining để cải thiện và tối ưu hóa kết quả. Data Mining và đánh giá kết quả là một quá trình liên tục, cho phép các Analyst và Data Scientist sử dụng các thuật toán tốt hơn và nâng cao chất lượng.

7+ Công cụ khai phá dữ liệu siêu hiện đại có thể bạn chưa biết
Những công cụ khai phá dữ liệu dưới đây không chỉ giúp bạn hiểu thêm Data Mining là gì mà còn hỗ trợ quá trình Data Mining cực chất lượng.
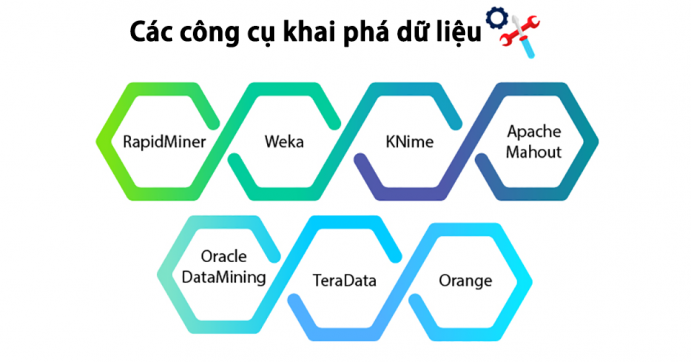
RapidMiner
RapidMiner là một công cụ phổ biến trong việc khai thác dữ liệu. RapidMiner được viết bằng Java và có giao diện đơn giản, không đòi hỏi kiến thức về mã hóa. RapidMiner cung cấp nhiều tính năng khai thác dữ liệu như tiền xử lý dữ liệu, biểu diễn dữ liệu, phân cụm, lọc và nhiều tính năng khác.
Weka
Weka là một phần mềm mã nguồn mở khai thác dữ liệu được phát triển tại Đại học Wichita. Giống như RapidMiner, Weka có giao diện đồ họa dễ sử dụng và không đòi hỏi kiến thức về mã lập trình. Weka cũng cung cấp các công cụ như trực quan hóa, phân loại, phân cụm, tiền xử lý và nhiều tính năng khác.
KNime
KNime là một bộ công cụ khai phá dữ liệu rất mạnh mẽ chủ yếu được sử dụng cho tiền xử lý dữ liệu và quá trình ETL (Trích xuất, Chuyển đổi & Tải). Ngoài ra, KNime tích hợp nhiều thành phần khác nhau từ khoa học và khai thác dữ liệu nhằm cung cấp một nền tảng toàn diện cho các hoạt động liên quan đến dữ liệu.
Apache Mahout
Apache Mahout là một phần mở rộng của nền tảng Big Data Hadoop. Nó chứa nhiều tính năng học máy như phân loại, hồi quy, phân cụm, và nhiều thuật toán khác, giúp xử lý và khai thác dữ liệu trong môi trường Big Data.
Oracle DataMining
Oracle DataMining là một công cụ mạnh mẽ cho việc phân loại, phân tích và dự đoán dữ liệu. Oracle cho phép người dùng thực hiện hoạt động khai phá dữ liệu trực tiếp trên cơ sở dữ liệu SQL để trích xuất thông tin và tạo biểu đồ.
TeraData
TeraData cung cấp dịch vụ kho chứa dữ liệu và các công cụ khai thác dữ liệu. Nó cho phép lưu trữ dữ liệu dựa trên mức độ sử dụng và cung cấp truy cập nhanh cho dữ liệu thường xuyên được sử dụng.
Orange
Orange là một phần mềm tích hợp các công cụ khai thác dữ liệu và học máy. Nó được viết bằng Python và cung cấp giao diện trực quan và thẩm mỹ cho người dùng.
Phân loại kỹ thuật trong Data Mining
Data Mining sử dụng nhiều kỹ thuật khác nhau trong các lĩnh vực khoa học đa dạng. Ví dụ, Pattern Recognition là một ứng dụng phổ biến của Data Mining, dựa trên nhiều kỹ thuật để phát hiện các mô hình trong tập dữ liệu. Dưới đây là một số kỹ thuật Data Mining phổ biến:
- Association rule mining: Sử dụng để xác định mối quan hệ giữa các phần tử dữ liệu thông qua các quy tắc if-then. Các tiêu chí hỗ trợ và đáng tin cậy đo lường hiệu suất và độ tin cậy của các quy tắc.
- Classification: Dùng để gán các phần tử dữ liệu vào các danh mục khác nhau trong quá trình Data Mining. Các ví dụ bao gồm cây quyết định (decision trees), bộ phân loại Naive Bayes và k-nearest neighbor.
- Clustering: Sử dụng để nhóm các phần tử dữ liệu tương tự vào các cụm khác nhau trong quá trình Data Mining. Ví dụ bao gồm phân cụm k-means, phân cụm theo cấp bậc (hierarchical clustering) và mô hình Gaussian mixture.
- Regression: Được sử dụng để tìm các mối quan hệ trong tập dữ liệu bằng cách tính toán các giá trị dự đoán dựa trên biến số. Ví dụ bao gồm hồi quy tuyến tính (linear regression) và hồi quy đa biến (multivariate regression).
- Sequence and path analysis: Giúp tìm kiếm các mẫu dữ liệu chuỗi cụ thể trong tập dữ liệu, đặc biệt là các mẫu dữ liệu nằm trong một tập hợp đối tượng hoặc giá trị cụ thể.
- Neural networks: Là một tập hợp các thuật toán được sử dụng để mô phỏng hoạt động của não người và áp dụng trong việc nhận dạng mẫu phức tạp trong học máy.
Giải đáp thắc mắc về Data Mining
Data Analysis là gì?
Data Analysis, hay phân tích dữ liệu, đề cập đến quá trình kiểm tra, làm sạch và biến đổi dữ liệu để tạo ra thông tin hữu ích. Sau đó, thông tin này được sử dụng để thảo luận và đưa ra quyết định.
Data Science là gì?
Data Science hay khoa học dữ liệu, là tập hợp các hoạt động liên quan đến việc thu thập, khai thác và phân tích dữ liệu để tìm ra thông tin giá trị và biến chúng thành hành động.
Sự khác biệt giữa Data Mining và Data Analysis là gì?
Data Mining tập trung vào việc tìm kiếm xu hướng hoặc mô hình trong dữ liệu. Data Analysis tập trung vào việc xác minh hoặc loại bỏ các giả thuyết.
Nên sử dụng công cụ nào để thực hiện Data Mining tốt nhất?
Có nhiều công cụ tốt cho Data Mining như RapidMiner, Oracle Data Mining, Apache Mahout, IBM SPSS Modeler, Weka,… Trước khi quyết định sử dụng một công cụ nào, nên thử nghiệm để đảm bảo phù hợp với nhu cầu của bạn. Chúc bạn thành công trong việc Data Mining!
Lời kết
Data Mining không chỉ giúp chúng ta trích xuất thông tin quý báu từ dữ liệu mà còn đóng góp vào quá trình ra quyết định thông minh, tối ưu hóa quy trình kinh doanh, và cung cấp cái nhìn sâu sắc về các mô hình và xu hướng ẩn trong dữ liệu. Qua những thông tin được cung cấp bên trên, hi vọng Wiki Lanit đã giúp bạn cái nhìn tổng quan về Data Mining là gì và lựa chọn được công cụ khai phá dữ liệu phù hợp. Nếu muốn biết sâu hơn và sử dụng Data Mining tốt nhất, bạn có thể tham khảo các khóa học Data Mining từ các chuyên gia uy tín.
Comments are closed.